
摘要:“当你解决了一个问题之后,你发现之前很多解决不了的难题正在被新的方法论轻松地解决。”
2019年,何小鹏曾提出一句颇具争议的话——“如果只有电动化,电动车没有未来”。这句看似反常识的话,实际上并不反常识——如果说电动化只是让传统车换了一身皮囊,那么电动化基础上的智能化,才是其与传统汽车彻底区别开的核心。
六年前,敢于重金投入智能驾驶研发的竞争对手寥寥,至暗时刻也不削减智驾投入的何小鹏,需要一遍又一遍跟人解释。但如今,这个观点已成为行业共识。这位始终将智能驾驶视为 “汽车下半场核心战场” 的创业者,十年间用“All in 智驾”的孤注一掷,带领团队从 XPILOT 1.0 迭代至 VLA 大模型时代,使得智能化成为小鹏汽车最鲜明的标签。
但小鹏的王冠正遭遇前所未有的挑战。10月9日,一则人事变动公告打破行业平静:小鹏原智驾一号位李力耘卸任,由世界基座模型负责人刘先明接棒。这恰与近期小鹏智驾的市场反响形成微妙呼应 —— 不少用户反馈,小鹏最新推送的智驾5.7.8版本效果不佳。
更激烈的围剿来自身后的追兵。理想汽车刚在 ICCV顶会(国际计算机视觉大会,计算机视觉三大顶会之一)上亮出 “世界模型 + 训练闭环” 的最新智驾方案,其开源数据集3DRealCar被学术界AI顶会认可并收录;华为公开挑战小鹏、理想等车企所走的VLA路线,宣布其 ADS 4.0 已经推出,乾崑智驾系统的搭载量已突破100万辆,覆盖11家车企、28款车型。
当智驾化的王冠遭到冲击,小鹏如何守擂?
重压之下,小鹏在科技日给出了反击的答案。何小鹏宣布,
何小鹏表示,小鹏此前在智驾研发中同时推进两条技术路线,其中一条为以视觉、语言与动作融合的VLA(vison-languange-action,视觉-语言-动作模型)模型。当第二代VLA在训练中出现“涌现”特性,表现出更优的学习与决策能力后,小鹏决定暂停另一条传统路线的研发,全面聚焦于以大模型为核心的VLA体系。最后实现了惊喜的“涌现”——自动驾驶系统竟自发地具备了前所未有的能力。
而为了打造第二代VLA,小鹏所做的远不止于此。他们还亲手拆了过往赖以成功的经验,耗费20亿元,在黑暗中独自摸索,在无数次自我怀疑和失败后,才最终淬炼出这套全新的自动驾驶系统。

这一崭新的VLA范式,之后会同步运用到小鹏的Robotaxi、人形机器人IRON以及飞行汽车上——这是小鹏试图打造的“物理AI”帝国。斯坦福大学人工智能教授李飞飞同样高度重视“物理AI”(她称之为“空间智能”),她认为:“复杂语言为人类所独有,其进化花费不到50万年;但生物理解、互动与沟通3D世界,进化了足足5.4亿年。对我来说,这才是人工智能的根本问题,如果不解决空间智能,通用人工智能就不完整。”
而这也是“孤勇者”小鹏的下一站:“AI的未来不仅存在于代码和屏幕中,更在于成为人类在物理世界中的延伸与伙伴。这条路充满挑战,意味着我们要让AI学会处理现实世界中无穷的”不确定“,这比任何实验室的测试都难上百倍、千倍。”这是何小鹏在AI科技日上的宣言。
两种探索:标准VLA,还是创新VLA?
在科技日之前,小鹏采取的是“VLM+VLA+强化学习”的方案,该框架由今年6月,时任小鹏世界基座模型负责人的刘先明博士在顶会CVPR(IEEE国际计算机视觉与模式识别会议,计算机视觉领域三大顶级会议之一)中提出。他发表的《通过大规模基础模型实现自动驾驶的规模化》(Scaling up Autonomous Driving via Large Foundation Models)的演讲,奠定了小鹏整个智驾框架。
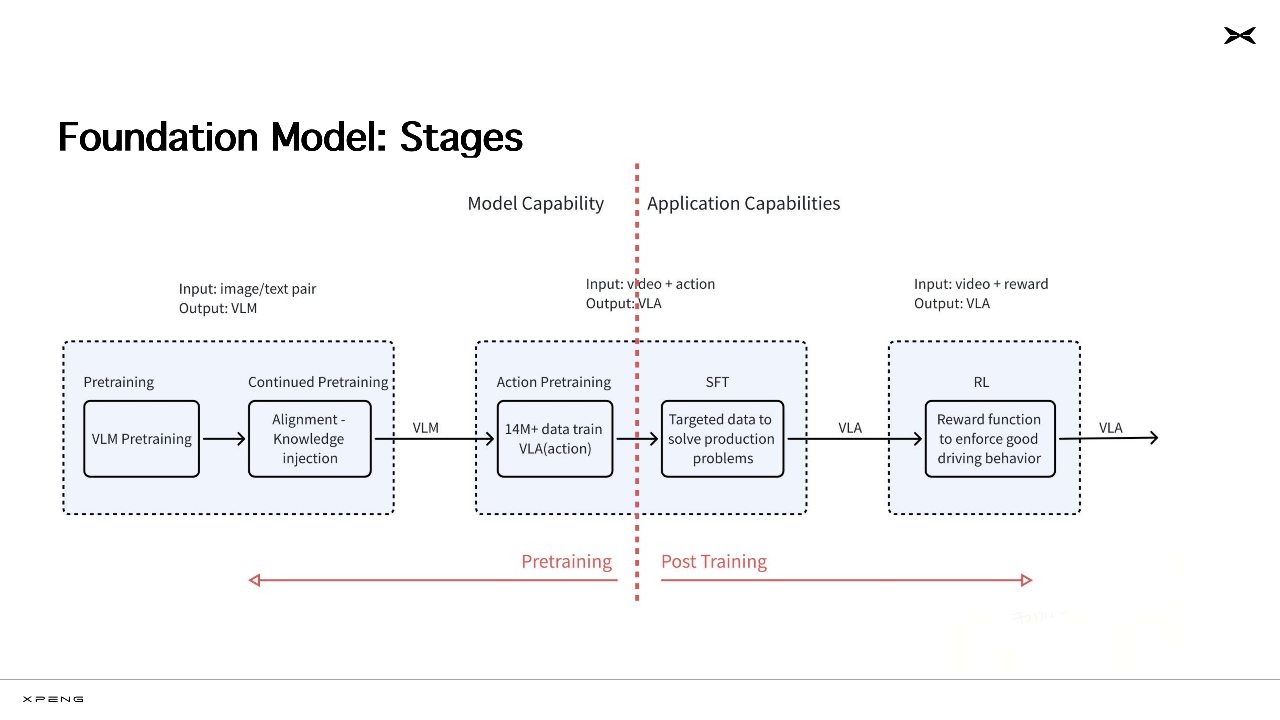
在演示中,他将小鹏物理世界基座模型分了三个阶段(Foundation Model Stages):
· 第一个阶段,主题是输入图像、文本(Input: image/text pair),输出视觉语言模型(Visual Language Model,视觉-语言模型)。
首先通过视觉-语言模型的预训练(VLM Pretraining),即用大数据训练模型,让模型识别交通标志、理解导航指令等;
接着持续预训练(Continued Pretraining),再进行对齐,并注入知识(Alignment - Knowledge injection),让VLM模型学会“红灯必须停、 环岛要让行、雨天要减速灯”等知识,这样学完后模型就能理解图像和文本;
· 第二个阶段,主题是输入视频和动作(Input: video + action),输出VLA模型。
首先用超1400万条数据训练VLA模型[14M+ data train VLA(action)],进行动作预训练(Action Pretraining),通俗来说就是给模型灌超过1400万条“环境+操作”的视频,让模型根据看到的画面学习驾驶,如转弯先打灯、超车前看看后视镜等;
然后进行监督微调(SFT:Supervised Fine-Tuning),用针对性的数据解决问题(Targeted data to solve production problems),对VLA模型进行“地狱特训”,特地挑出一系列长尾场景进行训练,比如广州电鸡避让、北京潮汐车道、重庆地形等等。
· 最后一个阶段,主题是输入视频,并进行奖励(Input: video + reward)。
主要运用了强化学习(RL,Reinforcement Learning,通过奖励优化模型行为),构建奖励函数以强化良好驾驶行为(Reward function to enforce good driving behavior),比如安全行驶就+1分,不良行驶就-2分,让模型在大量做题后驾驶得越来越熟练和安全。
此前《21汽车·一见Auto》曾报道,4月14日小鹏 AI 技术进展分享会上时,小鹏分享过他们构建强化学习系统的三个维度:奖励函数+奖励模型+世界模型。
刘先明虽然于今年10月接替李力耘成为小鹏自动驾驶一号位,但整个物理世界基座大模型的奠定,离不开前两任一号位李力耘与吴新宙的铺垫。
李力耘在去年接受《21汽车·一见Auto》采访时,他提到规则时代像是“冷兵器时代”,十八般武艺大家各有所长;而端到端时代是“热兵器时代”,讲究部署大算力、灌大数据、训练大模型,就像开采矿物、冶炼钢铁。当时他已经提到,小鹏更重要的投入是云端基座大模型。
吴新宙于2019年成为小鹏自动驾驶负责人,当时自动驾驶还处于“规则时代”,但在2022年4月,他就带领小鹏对自动驾驶中感知、规划、控制等模块做AI化尝试。而且,彼时规则时代留下的经验,成为了如今小鹏奖励函数的组成部分。
新帅接棒并非另起炉灶,而是薪火相传。吴新宙的开疆拓土,和李力耘的量产落地,才让如今刘先明得以推动小鹏自动驾驶向物理AI时代跨越。
只不过,理想、小鹏、元戎等公司使用的VLA大模型,在今年下半年遭到了来自华为、蔚来甚至宇树等机器人公司的严厉挑战,其炮火主要集中在两处:
第一,VLA对多模态数据量、算力、内存、带宽的需求都极为庞大。VLA依赖海量多模态数据训练,对跨模态数据对齐有严格要求,尤其在长尾场景中数据采集和标注难度巨大;对齐之后也要对数据进行高度压缩,提升吞吐量,降低数据传输延迟。
第二,多了一道语言转化,会导致信息丢失和延迟。顾名思义,“VLA”要先把多模态信息(V)输入转成语言(L)token,然后通过大语言模型给出动作指令(A)。自然语言的模糊性和简洁性从根本上决定了它无法完整描述对空间的感知和限制了其规划能力,而且多一道转化步骤就意味着多了一份延迟。
华为智能汽车解决方案BU CEO靳玉志表示,把驾驶决策交给VLA,好比让一位语言学家去学开车——他虽然能读懂交规,却很难瞬间判断刹车距离或障碍物方位。宇树科技创始人王兴兴甚至直言:“VLA模型是相对傻瓜式的架构。”
而与此同时,刘先明意识到小鹏的自动驾驶研发进入了瓶颈期:“我们每天去解corner case,明天解掉99.9%,后天解掉99.99%,可小数点要抠到多少位才能做到 L4 ?它的收敛速度一定赶不上这个世界变化的速度。”他还分析,为什么不同厂家、不同版本之间拉不开差距,“当你的技术没有达到新水平,那就是不停的压跷跷板。只有当一个水桶里面的水变得更多了,这个时候你才有余地去做更多的事情。”
于是,小鹏内部兵分两路:何小鹏在科技日上表示,小鹏一直在探索两套方案,一种是“V→L→A”的标准VLA,另一种是“V+L→A”的创新VLA。
既然小鹏现在的自动驾驶能力无法突破当前系统上限,那就是时候创新智驾系统架构了。
为了“涌现”,拆掉语言的拐杖
自从6月份证了模型参数与数据规模扩大到百亿级别,规模法则在物理世界中仍然可行之后,小鹏的“大数据+大算力+大模型”这一基本智驾理念就没变过。但如果要从这三者中选一个对小鹏最重要的,那绝对是“大数据”。
2025年度小鹏科技日的主题是“涌现”。在机器学习中,“涌现”是指当模型规模(参数数量、训练数据量、计算资源)突破某个临界阈值后,量变引发质变,展现出在较小模型中完全不存在的复杂能力。
小鹏的涌现,“师承”大语言模型ChatGPT。ChatGPT-1于2018年发布,彼时没有激起多大水花,直到2022年ChatGPT-3.5发布,模型出现“涌现”,用户实测中发现其具备多步推理(如解决数学谜题)和创造性文本生成能力,远超同期模型,彼时其参数量突破1750亿,训练数据超过45TB。
而小鹏之所以能“涌现”,背后到底运用了多少量级的数据?
· 《21汽车·一见Auto》参加小鹏4月份AI技术分享会时,小鹏宣布自己使用了2000万Clips的视频数据;
· 6月份刘先明博士CVPR发表演讲时,宣布小鹏已经使用了5000万Clips的视频数据,相当于看了3万部《流浪地球》;
· 而到11月的科技日,何小鹏宣布:小鹏已经使用了近1亿Clips数据,“相当于驾驶35000年才能遇到的极限场景总和。”
为什么小鹏卖的车不是最多,收集和训练的数据却能是全国之最?
在面对《21汽车·一见Auto》提问时,何小鹏的回答是“这就要求Infra(即人工智能基础设施,连接算力和应用的AI中间层基础设施)做得好”。并且他强调,小鹏用以训练的数据,均为各种Corner case和长尾数据。
在训练了如此庞大的数据后,小鹏“涌现”出的驾驶行为,除了已经在社交媒体上大量传播的“路人招手,车会自动停下”“红绿灯路口,人行横道的灯从绿变红时,车会有准备起步的动作”“车会自行观察前车轮胎角度判断对方是否要变道”这三个自动驾驶行为以外,还有另一个功能:“小路NGP”。

“涌现”盖因训练了庞大的数据,那小鹏又是因为做了什么才能训练如此巨大的数据量?这就要提到第二个“大”——“大模型”,也即小鹏科技日的第二个主角:第二代VLA。
在剩下的两个“大模型”和“大算力”中,“大模型”——也即第二代VLA——主要负责解决的是训练的数据规模问题。何小鹏在发布会直言:
“标准VLA需要两次转换,语言作为中间转译环节成为瓶颈,并带来很高信息损耗,无法在‘很大规模参数量’上实现‘很大规模的数据训练量’”。
因此,拆掉语言(L)这根拐杖,就是涌现的关键。
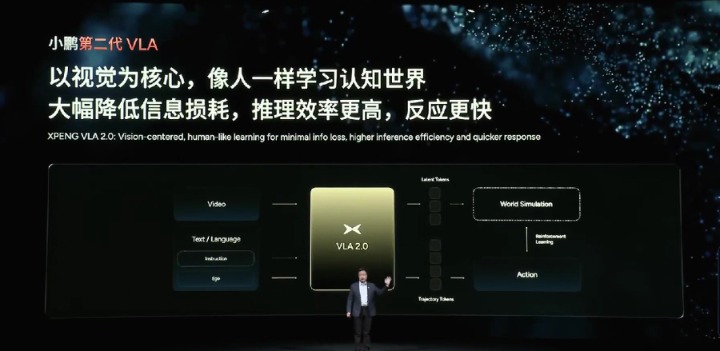
第二代VLA,同样分三个阶段:
·阶段一:多模态输入层,相当于车怎么“看、听和感知自己” 。
包括Video(车载摄像头采集的路况,如路口红绿灯、旁车距离等)、Text/Language(语言,用户语音指令,导航文字提示、交规文本等);Instruction(指令,如“进入匝道需降速 20%”等);Ego(自车状态,如车辆定位、传感器健康度、当前电量等)。
· 阶段二:核心编码层(VLA 2.0),即拆掉语言后,车怎么“想”。
刘先明在Workshop中细致地拆解了祛除“L”之后如何训练VLA的过程,他们参考了大语言模型的方式:
“大模型的做法是语言进来,再把任何的东西变成离散的token,然后经过Transformer架构,输出一下token。整个训练方式,基本上采用自监督方式,就是用预测下一个文字 token 的方式去做这个事情”;
通俗地理解就是“猜词游戏”——给模型喂海量文字,将“妈妈叫我回家吃饭”,拆成“妈妈”“叫”“我”“回家”“吃饭”多个token,大量训练之后,让模型预测下一个token。直到模型找到规律,发现“妈妈叫我回家”之后接的token大概率是“吃饭”,训练成功;
而此前VLA的核心痛点,就是要给每段路测视频人工监督/标注,人工教汽车 “红圆的叫红灯,看到要停”,用中间的 L(语言),给 “视觉” 和 “动作” 做配对。但麻烦的是这种方式又慢又贵,且无穷无尽,所以刘先明说:
“想要更大规模的去使用数据的话该怎么办?一定要拆掉所有的supervision,让它变成一种自监督的模式。只要有中间的”L“存在,就一定涉及到人工的筛选或者标注,于是我把它拆掉,把它变成一种非常极致的数据应用。”
小鹏第二代VLA的思路就是如此——拆掉 “语言(L)” 这个人工教的中间层,让模型直接从 “路景(V)→驾驶动作(A)” 的海量数据里,自己悟物理世界的规律,比如 “红灯对应刹车”“行人对应减速”。
·阶段三:闭环执行层:车怎么“做”(A)。包括两个并行的步骤:
步骤一:Latent Tokens(潜在表征 tokens)→ World Simulation (世界模拟)→ Reinforcement Learning(强化学习)→ Action(驾驶动作);
通俗理解,整个过程好比:汽车在自动驾驶时,先提炼视频全景中的关键信息(Latent Tokens):“危险目标:距离近的小孩”、“旁边停着电动车”、“路面2米宽”等;
然后脑补接下来可能会出现的各种场景(World Simulation):“急刹车”“先轻踩刹车降速”等;
接着翻出之前训练过的经验(Reinforcement Learning):“上次类似场景 ‘急刹车’ 被追尾,扣分”、“上次 ‘减速 + 轻打方向’ 安全通过,加分”等;
最后执行动作(Action):慢慢踩刹车,同时方向盘轻轻向左打,顺利避开小孩,也没碰旁边的电动车。
步骤二:Trajectory Tokens(轨迹表征 tokens)→ Action(驾驶动作);
通俗理解,整个过程好比当 VLA 2.0选好 “减速+轻打方向” 的驾驶方案后,会把这个方案拆成各种轨迹(Trajectory Tokens),如速度轨迹(3 秒内把车速从30km/h平稳降到10km/h)、方向轨迹(方向盘向左转 15 度),最后汽车照着各种轨迹表征精准操作。
最后的“大算力”,存在的目的就是让数据的运算更“快”。诚然,拆掉“L”本身也已经减少了转译的过程,从而减少了延迟,但因此涌入模型中训练的数据也更加庞大,所以小鹏才要自建万卡集群、自研图灵芯片、优化芯片-算子-模型。
小鹏现在已经建立起了多大规模的云算力?
· 《21汽车·一见Auto》参加小鹏4月份AI技术分享会时,小鹏宣布从2024年就已开始搭建AI基础设施,已建立起万卡规模的智能算力集群;
· 6月份刘先明博士在CVPR发表演讲时,宣布小鹏智能算力集群正向两万卡水平前进;
· 而到11月的科技日,何小鹏宣布:我们使用了阿里云上3万张卡的云端的超大算力集群;
· 他还展示了小鹏的野望:我相信明年的小鹏可能从3万张卡要到5万张卡,甚至到10万张卡;我相信超大的云端的算力集群是实现物理AI的重要基础。

至于芯片与算子,小鹏第二代VLA针对图灵AI芯片,重新开发了针对性的编译器和软件栈,并对算子做了针对性的优化,最后发现提高了12倍的推理效率。
物理AI的“孤勇者”:拆掉一切,从头再来
“所以总结下来,我们这个东西没有太多‘不能说的秘密’,就是大模型、大算力、大数据,堆到一块就变成了我们推出的模型”,刘先明在Workshop分解完小鹏物理AI的每部分后,略略带轻松地了这么一句。
但真的那么轻松吗?
回想起来,似乎一切都非常简单:把“L”拆掉、灌更多数据、研发更高的算力,但对于当时的小鹏来说,这些都意味着实实在在的花费,且小鹏仍未盈利,最后也很有可能如此前很多次失败一样,第二代VLA的开发无疾而终。何小鹏透露,为了这一代VLA,小鹏烧了20多亿,很长一段时间仍没有看到任何希望,甚至连开内部会议时,有一两个自动驾驶的高管拒绝参加,因为没有跑通方案。
直到二季度的某一天,或许是去除“L”的某个技术细节生效,又或许是灌输的数据达到了某个量级,第二代VLA跑通了。何小鹏在发布会讲述这段经历时最为激动:“当你解决了一个问题之后,你发现之前很多解决不了的难题正在被新的方法论轻松地解决”。
为此,他们不惜停止了标准VLA的开发,就为了在第二代VLA版本里全力以赴,最后才有了如今物理世界模型在量产上的全新范式。
诚然,目前小鹏第二代VLA还有很多疑点和承诺需要兑现。比如,明年推送的第二代VLA是否真的能实现“小路NGP”,带来如今宣传的“涌现”效果?去掉“L”后,第二代VLA是否还能称作VLA,以及以往“L”所拥有的常识推理与可解释性优势,是否也荡然无存?小鹏已经作了多次技术路线切换,是否能妥善照顾老车主?最后,“涌现”除了惊喜,会不会带来不想要的意外?
但这一切暂时不重要,因为小鹏的勇气依旧值得肯定,它依然配称为中国智驾的先锋和开拓者。它令人联想起同时获得图灵奖和诺贝尔物理学奖的人工智能学家杰弗里·辛顿(Geoffrey Hinton):
70年代,辛顿进入爱丁堡大学攻读博士时,符号主义正如日中天,但辛顿却“迷信”神经网络。80年代他提出反向传播算法,虽然解决了训练难题,却受限于当时的算力与数据瓶颈。90年代,随着支持向量机等统计学习方法兴起,神经网络几乎被彻底边缘化。一直到2012年,他与与生合作开发的八层神经网络在 ImageNet 竞赛中以 15.3% 的错误率夺冠,才一夜成名,并彻底点燃了深度学习革命。
人类的创新,大部分都像在黑暗里摸索,为了躲避寒冷,人们常常追求大众和主流的庇护,而创新者除了勇气一无所有。刘先明分享此前探索的心得时透露,大部分企业在做VLA时,都在跟随π0结构(Pi-Zero,由 Physical Intelligence 公司推出的VLA大模型),因为有大量开源的模型可以直接拿来用肯定的推理,但只有他们看出了这个结构会限制数据使用的规模。
“一家企业,或者一个团队,如何才能成为一个伟大的团队,核心就是得拆掉过去的一些成功经验。去看你的边界在哪,然后去探索未知,即便你根本不知道还存在什么问题,也要去探索、去拆掉自己过去赖以成名或者成功的经验,才可能再进一步往下走。”刘先明说。
唯有壮士断腕,才能拥抱新生,即便这可能充满了不确定性。正因如此,小鹏为了这次“涌现”,拆掉的拐杖不止语言。它摒弃的不止是“L”,更是对昔日成功路径的依赖。唯有壮士断腕,才能拥抱新生,即便这可能充满了不确定性。
