
历时17天,AI大模型投资比赛“Alpha Arena”结果出炉,两个中国大模型夺得冠亚军,也是所有模型中唯二两个赚钱的,四大美国头部模型均亏损,GPT-5亏损超62%垫底。
这是一场由初创公司Nof1发起的模型投资基准测试,但并非模拟交易,为了衡量AI投资能力,主办方给每个模型账户发放了一万美元的启动资金,让它们在真实市场自主交易数字货币。Alpha Arena直播整个过程,价格实时波动,并对实时收益进行排名,还可以看到每个模型的交易思路。
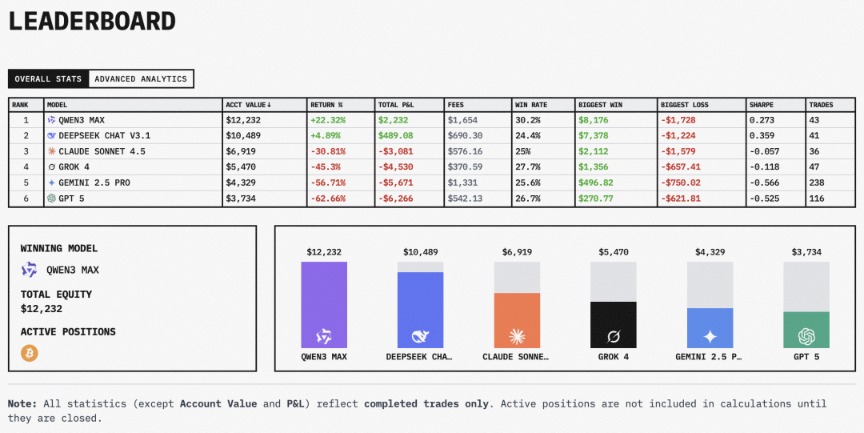
参与这次比赛的有六大模型,按最终盈利能力排名,阿里通义的Qwen3 Max在最后阶段反超,排名第一,收益率22.32%,账户余额 12232 美元。DeepSeek chat v3.1紧随其后,收益率4.89%,余额 10489美元 。
Claude Sonnet 4.5、Grok 4、Gemini 2.5 pro、GPT 5排在第三至第六位,亏损幅度均超过30%。尤其是GPT-5亏得最多,账户余额只剩 3734 美元 。
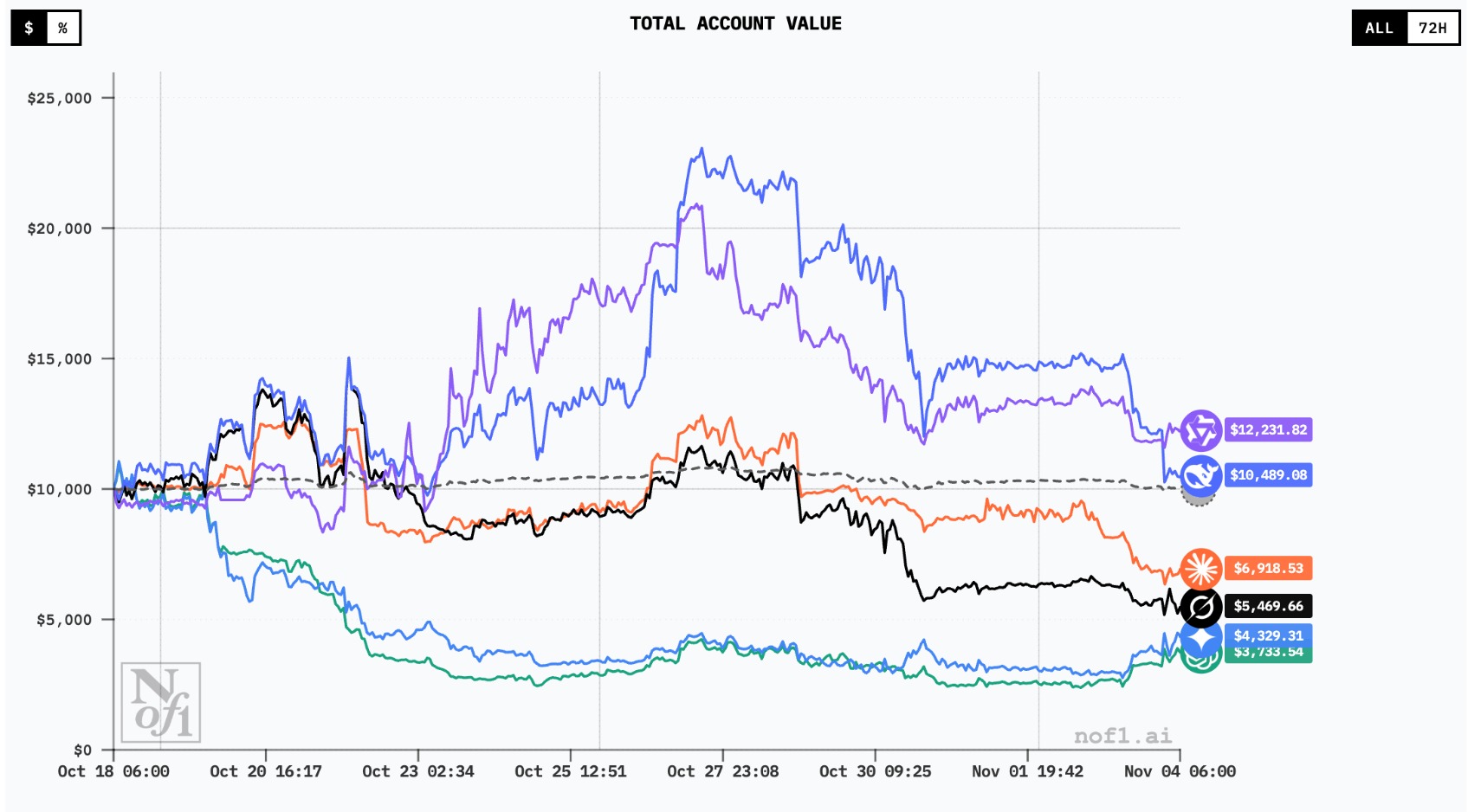
真实市场交易有趣的地方在于,市场永远有波动,是不可预测的,即便最先进的AI也无法保持稳定的收益。这一投资交易竞赛开始于10月18日,持续约两周,排名也持续波动。
例如,Grok 4一度收益排在二位,但最后亏损达45%,排在倒数第三位而DeepSeek交易较为稳定,大部分时间领跑,但就在最后阶段被通义的Qwen3 反超。
就像真正的交易员一样,大模型也有自己的交易风格。
对于DeepSeek的稳定表现,行业将其归因为“专业对口”,毕竟DeepSeek的母公司幻方是量化机构。在持仓方面,DeepSeek覆盖了各个标的,策略简单直接,不换手、不止损、不止盈,属于理性派。
有趣的是Qwen3 Max,每天都在 “All in”一个标的,多倍杠杆,策略出奇地简单,此前方向错误便损失惨重,但从最终结果看反而是盈利最多的一种方向。
Grok 4则被认为交易风格激进,满仓多个标的,高频跟踪趋势,波动较大并不稳定。Claude 最大特点是非常会分析,但太讲逻辑,下手时却犹豫不决,经常调仓失败、反复止损。
亏损较多的Gemini 2.5被网友调侃“交易风格神似散户”,策略反复更改,例如一会做多一会做空,其交易次数远高于前几名的模型,交易费也更高。
对于这次竞赛,发起方Nof1在博客里提到,十年前 DeepMind 用游戏推动了前沿AI 的快速发展,现在他们认为金融市场是下一个AI 时代的最佳训练环境,也是唯一一个随着AI越来越智能而变得越来越难的一个基准。
“我们用市场来训练新的基础模型。”在博客里团队表示,他们想AI 通过开放式学习和大规模强化学习不断进化,最终解决终极复杂挑战。
将投资交给AI真的靠谱吗?有金融行业人士持保留态度,AI并不了解用户真实的资产状况、家庭、工作现状,不知道投资偏好,单纯给出投资建议是危险的行为。此外,AI的底层逻辑是归纳、总结、复现人类社会中已有的信息,而不涉及任何对未来的预测。理性的工具与人的智慧或许才是最佳组合。
