
一度被誉为“地表最强AI(人工智能)生图模型”的谷歌Nano Banana Pro,其引发的新一轮技术热潮尚有余温,视频生成模型“大混战”又在年末迎来高潮。
先是海外AI视频初创公司Runway发布了新一代视频模型Gen-4.5,并在基准测试中超越谷歌的Veo3登顶。12月1日,快手可灵AI又丢出“王炸”,上线“全球首个统一多模态视频大模型”可灵O1,再次强化了其作为“生产力工具”的一面。
火药味很浓。
一般而言,普通C端(消费者)用户想生成相对较复杂和精细的视频,往往需要使用生图模型、视频生成模型以及剪辑软件等进行制作。实际操作中,多模型、多软件的切换比较耗时且繁琐,视频效果也可能会在流转中出现主体一致性差、动作崩掉等情况,需要重新“抽卡”(需要通过反复尝试、调整提示词或参数来获得理想作品的过程)。
“统一多模态视频大模型”据称主要解决的就是这个问题。
事实上,从去年开始,视频生成领域的竞争就已进入白热化。今年,国外的Sora2、Veo3逐渐确立统治地位,国内有多轮大版本更新且商业化速度一骑绝尘的可灵不断出招。时至年末,新一轮混战来袭,谁是“地表最强视频生成模型”,我们离答案还有多远?《每日经济新闻》记者对可灵O1进行了实测。
支持多模态,输入文字指令就能“P视频”
《每日经济新闻》记者实测发现,可灵O1首次将参考生视频、文生视频、首尾帧生视频、视频内容增删及修改变换等多任务,融合于大一统模型之中。
最重要的是,完成上述任务可以“全流程语义控制”,用一句话就可以生成或修改视频。图片、视频、主体、文字等都可以被视为指令,可灵O1可综合理解用户上传的照片、视频或主体(一个角色的不同视角)的意图,生成视频的各种细节。
具体而言,记者实测发现,在可灵O1模型的多模态指令输入区,可以上传1到7张参考图或主体,自由组合人物、角色、道具、服装、场景等元素,让静态元素在视频中动起来。
视频生成后,也可以在输入区进行指令的变换,对原视频进行主体与背景的增加、修改、删除,也可以修改风格、颜色、材质、视角等。由于支持多模态输入,这个修改的过程可以由文字、图片、主体的输入语言任意组合。
比如,在输入区输入“删除【视频】中道路两侧的路人,保留马车”,修改后的视频保持了主体的一致性,对被删除的内容进行了相对干净的抹除。

图片来源:可灵O1测试截图
除了用文字指令删除、增加内容外,还可以用图片指令修改视频的主体等。比如,输入“将【视频】中的雕像修改为【图片】中的姜饼人”,生成的视频保持了原视频的运镜逻辑、背景一致,主体也按要求进行了替换。

图片来源:可灵O1测试截图
此外,可灵O1还可以改变视频的视角、景别,比如远景变特写、俯拍变仰拍等,并支持用参考视频内容进行新镜头的生成等。
如记者输入图片和视频两段素材,让图片中的静态主体以视频主体的舞蹈方式动起来,结果生成视频对原图片打光、色调以及主体形象的还原度相对较高,但也有一些小瑕疵,如手部细节模糊、人物身体比例不协调等,还需要重复“抽卡”。
视频“一致性”有所提高,指令还可叠加使用
体验时记者注意到,可灵O1强化了输入图像及视频的理解,支持多视角图创建主体。也就是说上传一个角色的多视角照片,其可以在不同镜头、不同光照与风格下保持“同一个人”的特征不变。
比如,记者输入近期大热电影《疯狂动物城》主角“朱迪”的多张不同主体视角图片,在后期进行视频生成时,无论主角、道具、场景以及运镜如何变化,朱迪的主体形象都能够保持相对稳定。
不过,当记者添加了狐狸尼克的图片参考并进行更复杂的视频输出时,主体之外的人物形象出现不合逻辑的动作、形态呈现,甚至有一组舞会成员随着镜头推移,从双人跳舞变成了三人跳舞,需要重复“抽卡”。
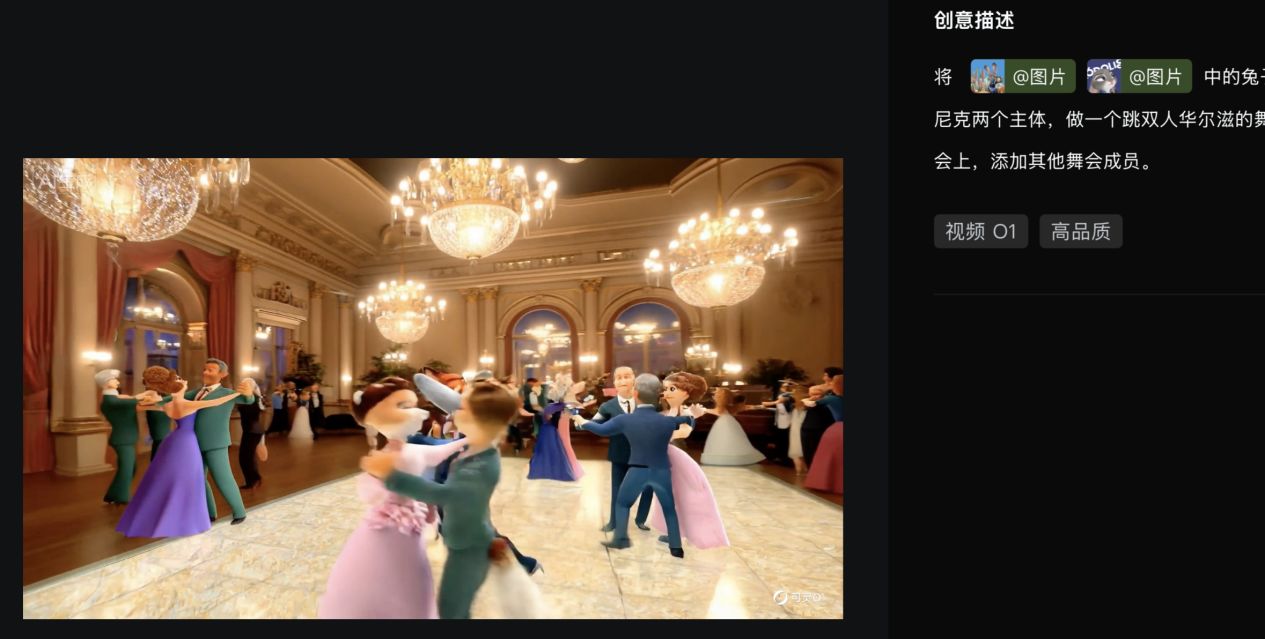
图片来源:可灵O1测试截图
此外,记者体验时还发现,不仅限于单个角色或物品,可灵O1还具备多主体融合能力。可以自由组合多个不同主体,或将主体与参考图混搭。这种能力适用于视频里呈现复杂的群像戏或互动场景中,模型能够独立锁定及保持每一个角色或道具的特征。不过,这个功能需要提供高清、主体明确的图片,否则需要重复“抽卡”。而在复杂的互动场景下,多个主体的互动指令也需要更明确地描述,不然就难以避免重复“抽卡”。
在实际场景落地中,如宣传视频就可以直接上传商品图、场景图等,通过多个主体相互组合快速完成视频生成。

图片来源:可灵O1测试截图
记者发现,除单点任务外,可灵O1还支持组合不同的技能,允许把各种指令叠加使用,一次性生成出来。比如,可以组合参考图片和修改视频风格,两个动作同时进行。
这些功能的升级,相对能够拓宽可灵的场景应用,特别是作为“生产力工具”,可应用于影视创作、创意广告、服装穿搭参考视频、视频后期制作等。
不过,有不少网友表示,目前可灵视频O1模型的使用价格较贵,视频生成、修改成本高。据了解,视频价格取决于输入情况和生成视频长度——无视频输入时,8灵感值/秒,有视频输入时,12灵感值/秒。以单次购买一个月的可灵黄金会员价格为例,66元/月、每月有660灵感值。如无视频输入,生成一个高品质5秒视频,大约需要40灵感值。
技术狂欢背后:可灵年收入即将破10亿元,C端市场待垦
视频、图像O1模型上新后,12月3日,可灵又官宣推出视频生成2.6模型。记者注意到,该模型提供了“音画同出”能力,升级了文生音画、图生音画两大功能。目前,语音支持生成中文与英文,生成的视频长度最长可达10秒。
12月4日晚,新一代可灵数字人2.0宣布即日起正式全量上线。上传角色图、添加配音内容、描述角色表现,三步即可生成。相对旧版,新版在表现力、手部及口型精准控制上有提升,且支持最长5分钟的视频时长。
除了在年末迎来“技术周”,前不久三季度财报披露时,可灵宣布2025年收入将达10亿元的商业化进程,再次引起不小的市场反应。
值得一提的是,目前可灵用户构成仍以B端客户为主。而随着Open AI正式发布的第二代AI视频生成模型Sora 2等将视频生成与社交互动深度融合,C端消费级应用的落地进程明显加快。
快手科技创始人兼首席执行官程一笑在三季报电话会上也指出,“当前我们的主要精力依然是面向专业创作者,但未来也会将可灵的技术能力进一步产品化,与社交互动结合,加速C端应用的商业化。”这也回答了可灵未来增长方向的问题。
工信部信息通信经济专家委员会委员盘和林此前接受《每日经济新闻》记者微信采访时表示,视频生成赛道的最终受益者,可能还是内容创作平台,因为这些平台具备两样东西:其一,是最相关的用户群体,未来视频生成可能更多还是为短视频自媒体服务;其二是最大规模的用户受众,生成式AI带来的内容创作上的升级,会进一步影响创作者和观看者。
“未来,快手平台上的创作者,需要借助可灵这样的AI工具来生成内容,或者至少辅助内容创作,这会大大提高平台内容输出的质量,从而更好地吸引用户,扩大快手在内容平台领域的影响力。”盘和林如此补充。
