
广东财经大学信息学院提出基于深度强化学习的股票交易决策算法LSTM-DDPG,在多项实验中获得出色表现。

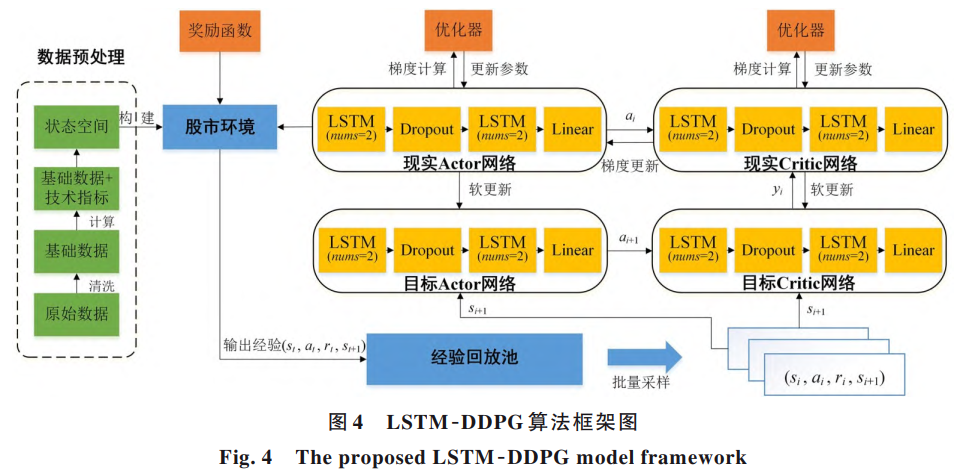
算法由两种子模型融合而来。长短期记忆网络擅长从时间序列数据中捕捉长期依赖关系,比如股票价格随时间变化的趋势与周期;深度确定性策略梯度则是一种常用于机器人控制、游戏等场景的强化学习方法,能够在高维、连续的动作空间中作出决策。研究团队将二者结合,构建出一个能够根据市场状态自动执行买入、卖出或持有决策的智能系统。
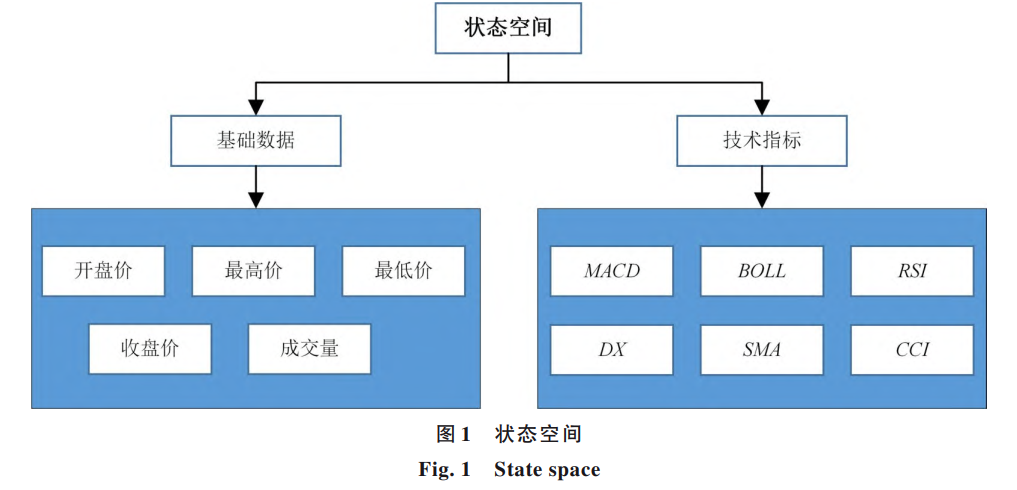
为了使算法更贴合真实交易环境,研究者还在模型中引入了六项经典技术指标,包括平滑异同移动平均线、布林线、相对强弱指标等。这些指标常用于传统股票分析,能够帮助算法更全面地理解市场情绪、价格动量和波动情况。
此外,研究还设计了两种不同的奖励机制:一种是追求累计收益最大化,适合愿意承担较高风险以博取更高回报的投资者;另一种则是基于夏普比率,更注重风险调整后的收益,适合希望平衡收益与安全性的投资者。
在实验部分,研究团队分别在美国和中国市场进行了测试。单只股票交易中,选取了苹果和格力电器作为标的;在投资组合任务中,则使用了道琼斯工业指数成分股和中证100指数成分股。
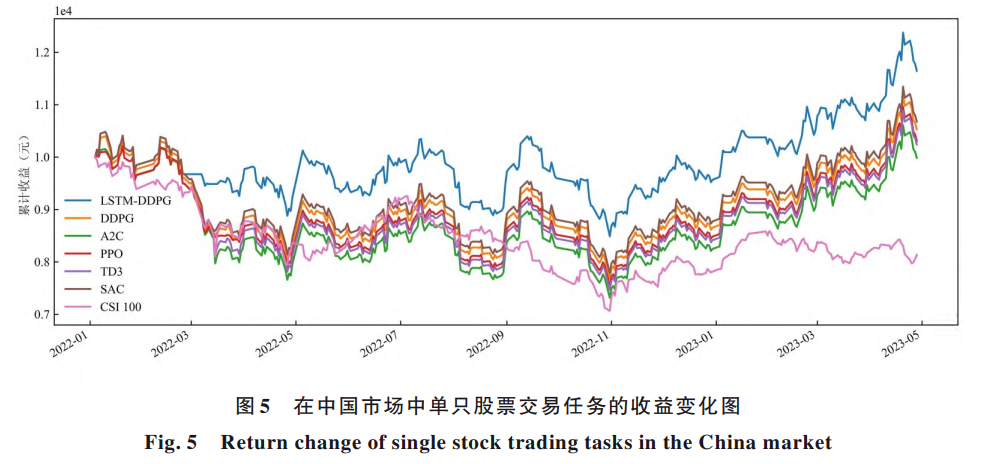
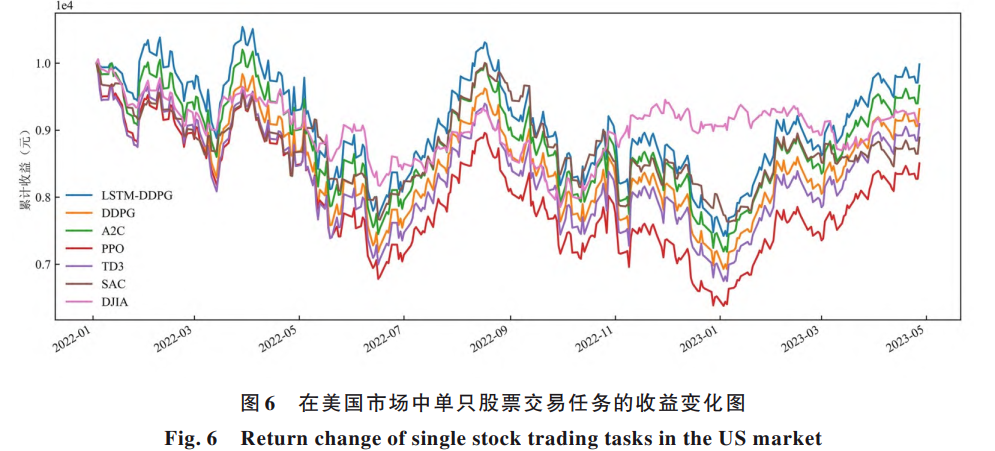
结果显示,无论是单一股票还是多股票组合,LSTM-DDPG在累计收益、夏普比率、卡玛比率等多个指标上,多数情况下都优于传统的深度强化学习方法及市场基准指数。尤其是在投资组合管理中,该算法在控制波动的同时,仍保持了相对稳健的收益表现。
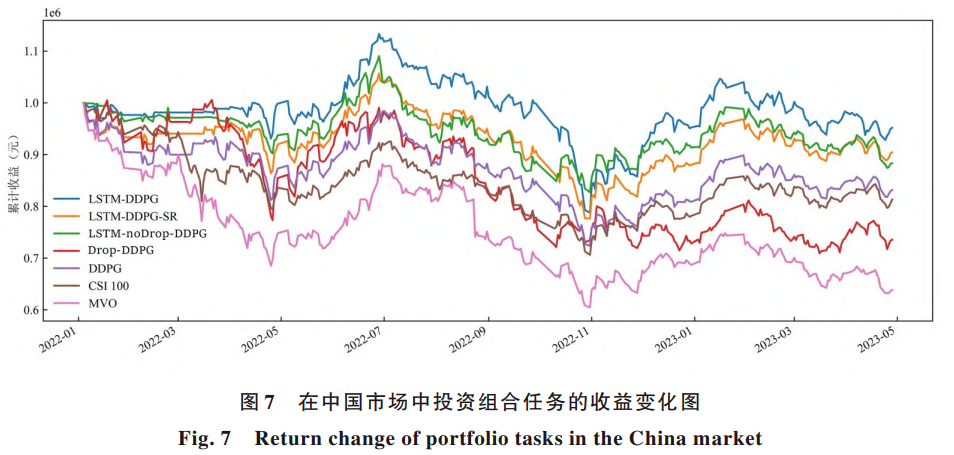
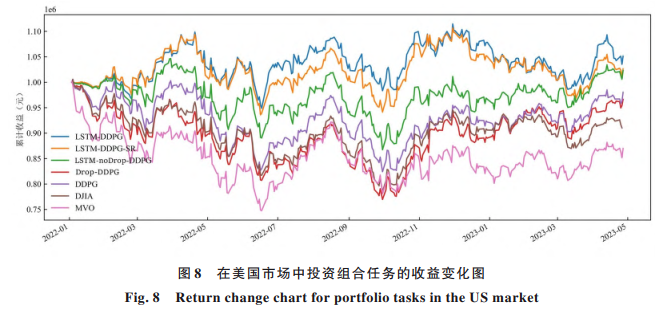
研究中还进行了一系列消融实验,即逐步移除模型中的某些组件,观察其对效果的影响。结果显示,在LSTM层后加入随机丢弃操作有助于防止模型过度拟合训练数据,提升泛化能力;而如果仅简单地在原有网络上添加该操作,反而可能导致性能下降。
尽管该算法展现出人工智能在金融交易中的潜力,但投资者也应保持理性态度。市场永远充满不确定性,任何模型都无法完全预测未来走势。尤其是在实际交易中,手续费、滑点、流动性等因素都可能影响最终收益。此外,该研究基于历史数据训练与测试,市场环境变化可能对模型实际应用带来挑战。#社区牛人计划##技术面分析##投资干货#
