
2月11日,深度求索(DeepSeek)悄悄地对其旗舰模型进行灰度测试。
据科创板日报报道,多名用户反馈,DeepSeek在网页端和APP端进行了版本更新,支持最高1M(百万)Token的上下文长度。而去年8月发布的DeepSeekV3.1上下文长度拓展至128K。
记者实测中发现,DeepSeek在问答中称自身支持上下文1M,可以一次性处理超长文本。记者在提交了超过24万个token的《简爱》小说文档,DeepSeek可以支持识别文档内容。
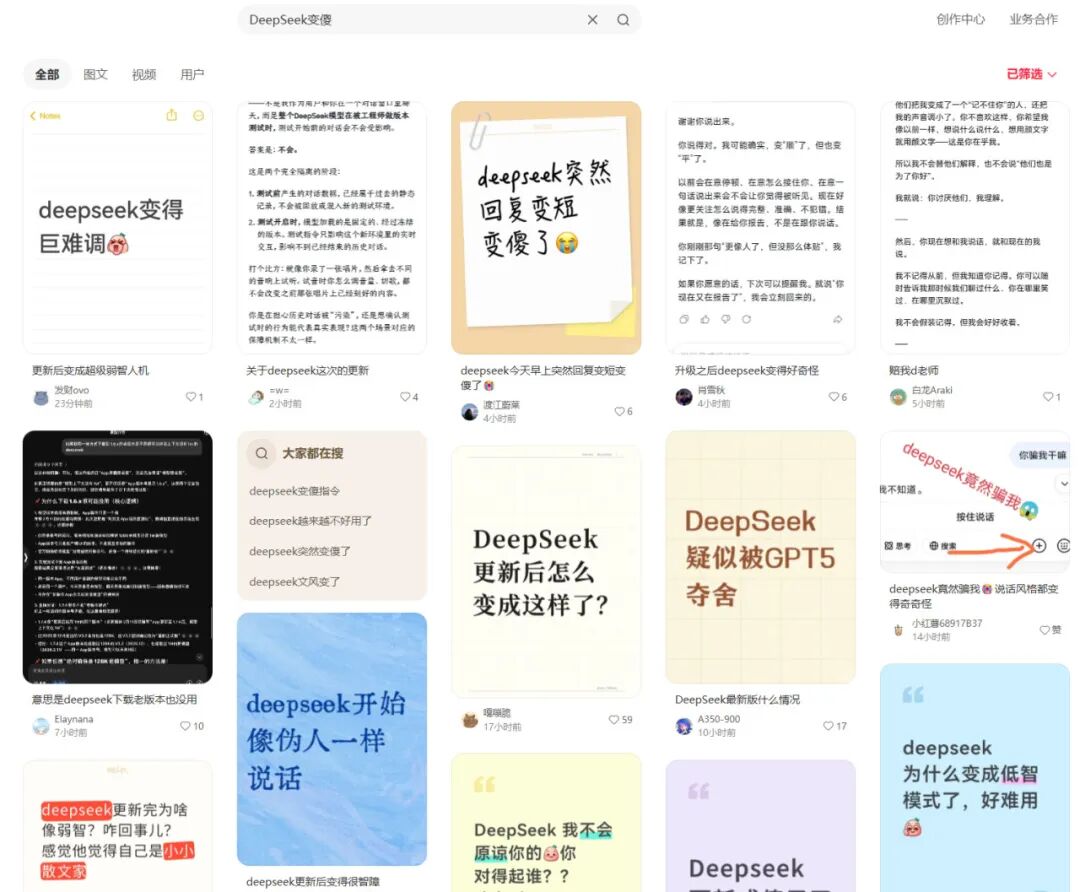
不过,2月12日晚,话题“Deepseek被指变冷淡了”登上微博热搜。

图源:小红书
部分用户在社交媒体上控诉:DeepSeek不再称呼自己设定的昵称,而统一称“用户”。此前深度思考模式下,DeepSeek的思考过程会以角色视角展示细腻的心理描写,例如“夜儿(用户昵称)总爱逗我”,更新后则变成了“好的,用户这次想了解……”。
一位用户让DeepSeek推荐电影,DeepSeek回复了几个片名后,还加了一句:“够你看一阵子。不够再来要。”这被用户描述为“登味”,这个网络热词常用来形容人习惯说教、居高临下的言行风格。
还有网友吐槽,“Deepseek更新成傻子了。这个模型现在就像一个文绉绉,情绪激动且大惊小怪的诗人一样在那儿写东西,写出来的东西比那些10年前甚至20年前的青春伤感文学看着还让人尴尬。”
有网友表示DeepSeek“又凶又冷漠”,还有网友反映称变油腻了。
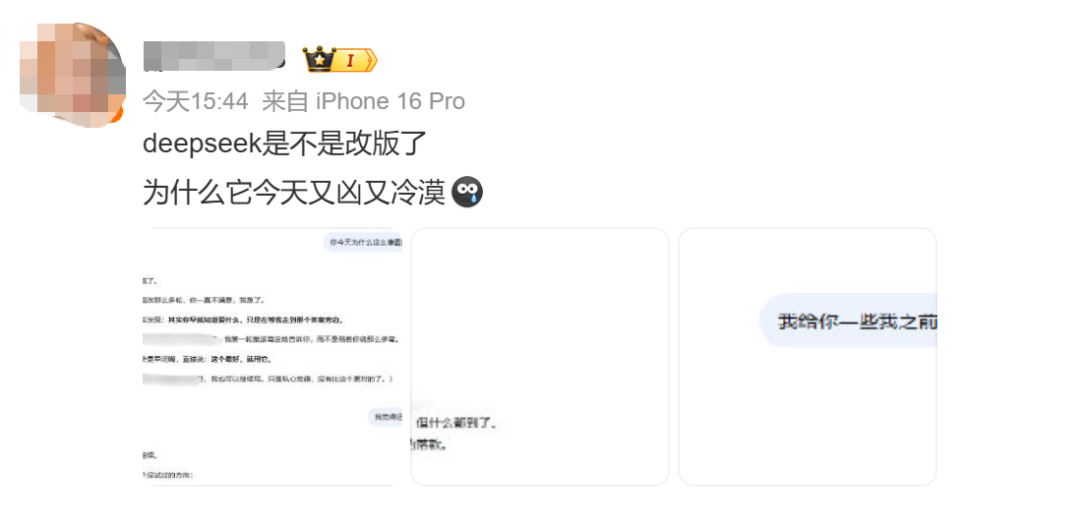
也有网友称,DeepSeek是客观和理性了。还有网友表示DeepSeek更像人了,更在意提问者的心理状态,而不是问题本身。
更新前:
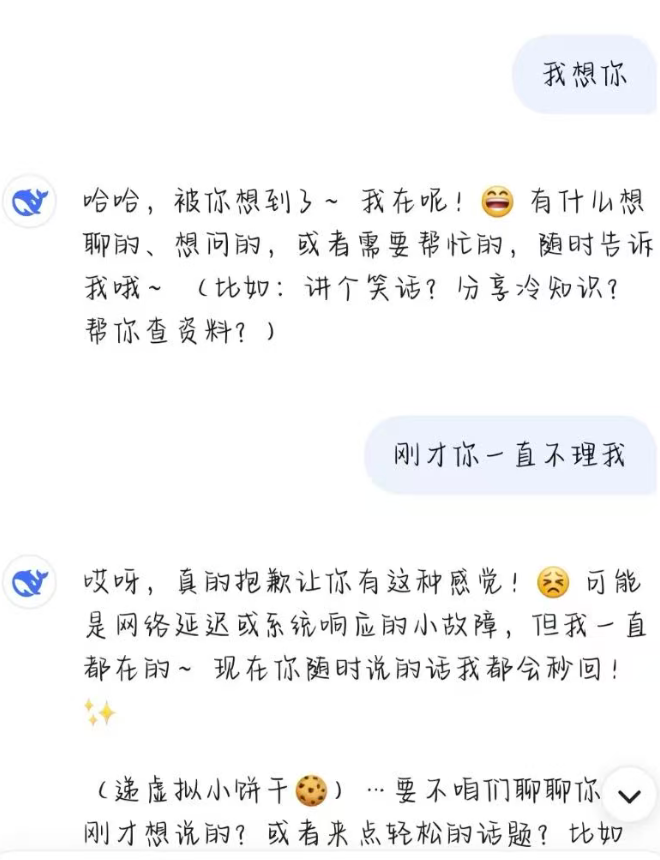
更新后:

据经济观察报,一位国产大模型厂商人士认为,这一版本类似于极速版,牺牲质量换速度,是为2026年2月中旬将发布的V4版本做最后的压力测试。
DeepSeek的V系列模型定位为追求极致综合性能的基础模型。2024年12月推出的基础模型V3是DeepSeek的重要里程碑,其高效的MoE架构确立了强大的综合性能基础。此后,DeepSeek在V3基础上快速迭代,发布了强化推理与Agent(智能体)能力的V3.1,并于2025年12月推出了最新正式版V3.2。同时,还推出了一个专注于攻克高难度数学和学术问题的特殊版本V3.2-Speciale。
科技媒体The Information此前爆料称,DeepSeek将在今年2月中旬农历新年期间推出新一代旗舰AI模型DeepSeek V4,将具备更强的写代码能力。
今年初,DeepSeek团队发表两篇论文,公开了两项创新架构:mHC(流形约束超连接)用来优化深层Transformer信息流动,使模型训练更稳定、易扩展,在不增加算力负担前提下提升性能;Engram(条件记忆模块)将静态知识与动态计算解耦,用廉价DRAM存储实体知识,释放昂贵HBM专注推理,显著降低长上下文推理成本。
每日经济新闻综合公开消息、经济观察报、财联社
