
12月1日,DeepSeek微信公众号宣布,今日发布两个正式版模型:DeepSeek-V3.2和DeepSeek-V3.2-Speciale。
DeepSeek-V3.2的目标是平衡推理能力与输出长度,适合日常使用,例如问答场景和通用Agent任务场景;DeepSeek-V3.2-Speciale是DeepSeek-V3.2的长思考增强版,并结合了DeepSeek-Math-V2的定理证明能力,目标是将开源模型的推理能力推向极致,探索模型能力的边界。
DeepSeek表示,在公开的推理类Benchmark测试中,DeepSeek-V3.2达到了GPT-5的水平,仅略低于Gemini-3.0-Pro;相比Kimi-K2-Thinking,V3.2的输出长度大幅降低,显著减少了计算开销与用户等待时间。
DeepSeek-V3.2-Speciale模型具备出色的指令跟随、严谨的数学证明与逻辑验证能力,在主流推理基准测试上的性能表现媲美Gemini-3.0-Pro。V3.2-Speciale模型在IMO 2025(国际数学奥林匹克)、CMO 2025(中国数学奥林匹克)、ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛)及IOI 2025(国际信息学奥林匹克)中取得金牌水平的成绩。其中,ICPC与IOI成绩分别达到人类选手第二名与第十名的水平。
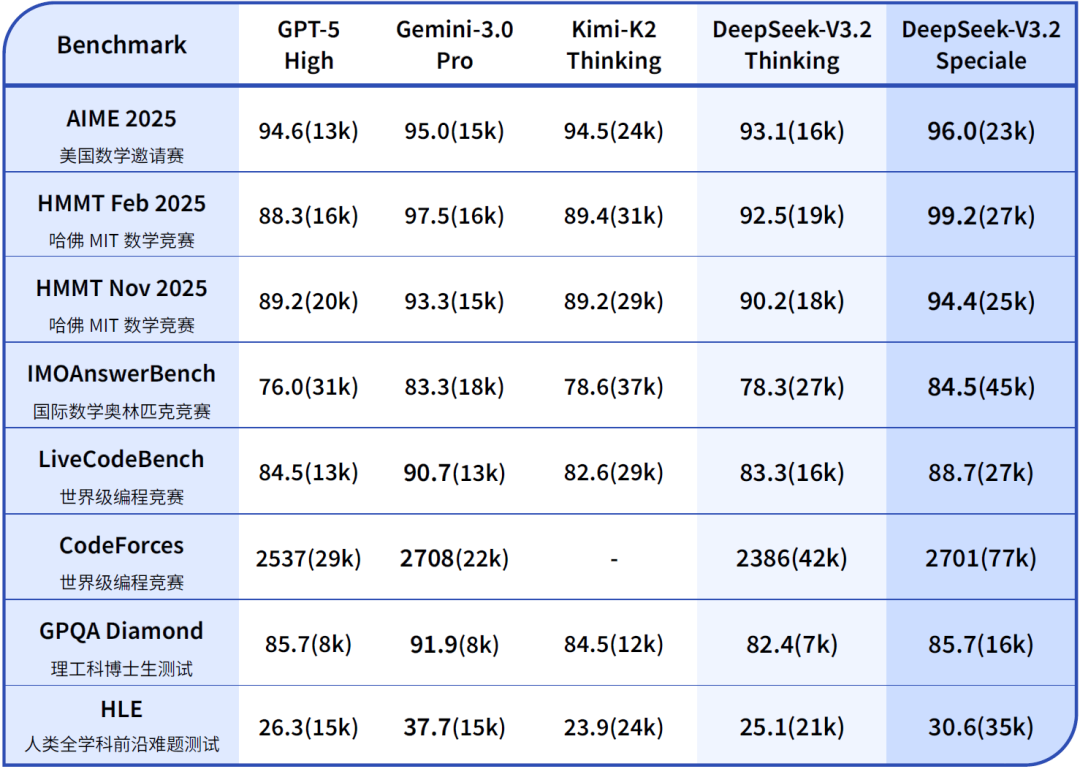
DeepSeek-V3.2与其他模型在各类数学、代码与通用领域评测集上的得分(括号内为消耗Tokens总量约数) 图片来源:DeepSeek微信公众号
从数据来看,在高度复杂任务上,Speciale模型大幅优于标准版本,但消耗的Tokens也显著更多,成本更高。DeepSeek表示,目前DeepSeek-V3.2-Speciale仅供研究使用,不支持工具调用,暂未针对日常对话与写作任务进行专项优化。
在使用上,不同于过往版本在思考模式下无法调用工具的局限,DeepSeek-V3.2是DeepSeek推出的首个将思考融入工具使用的模型,并且同时支持思考模式与非思考模式的工具调用。公司通过提出一种大规模Agent训练数据合成方法,构造大量难解答、易验证的强化学习任务,提高模型的泛化能力。
公司表示,DeepSeek-V3.2思考模式增加了对Claude Code的支持,但未充分适配Cline、RooCode等使用非标准工具调用的组件,因此建议用户在使用此类组件时继续使用非思考模式。
DeepSeek表示,DeepSeek-V3.2模型在智能体评测中达到了当前开源模型的最高水平,大幅缩小了开源模型与闭源模型的差距。公司表示,V3.2并没有针对这些测试集的工具进行特殊训练,并据此认为V3.2在真实应用场景中能够展现出较强的泛化性。
