一石激起千层浪,一则消息让中国算力市场再度泛起涟漪。
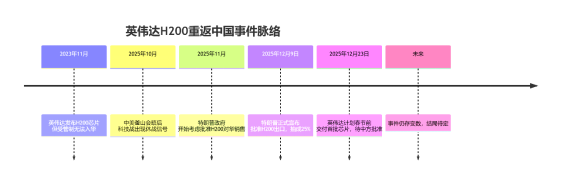
据报道,人工智能芯片巨头英伟达已告知其中国客户,公司计划于明年2月中旬,即农历春节前,交付其当前性能排名第二的AI芯片H200。有消息人士透露,英伟达将动用现有库存来履行首批订单,预计发货总量在5000至10000套芯片模组之间,折合约4万至8万颗H200芯片。$英伟达(NASDAQ|NVDA)$$胜宏科技(SZ300476)$$鸿博股份(SZ002229)$
如果以每套8卡模组140万元人民币的单价计算,这笔交易的总价值将高达70亿至140亿元。
这个H200芯片是什么来头?它是英伟达仅次于Blackwell、Rubin系列的次顶级芯片,H200性能较此前的“特供版”H20提升约6.7倍,在拜登政府时期被禁止对华出口。
本次H200的放行看似突然,实则有迹可循。早在12月9日,美国总统特朗普已在社交媒体上宣布:“美国将允许英伟达向中国‘经批准的客户’出售H200人工智能芯片,但销售收入的25%将上缴美国政府。”
对英伟达和美国而言,此举不失为一个“好买卖”。一方面能消化库存维持客户关系,借此提振英伟达业绩和美股表现,同时用‘次优解’延缓中国AI发展速度,可谓一箭双雕。
那么对于国内算力产业链,如若H200如期回归,将会产生什么影响?
国产大模型及算力配套设施:
今年以来,我国大模型快速发展,Deep-Seek、Qwen等开源模型在全球社区影响力迅速提升,下载量位居前列。在全球公认百万用户盲测的大模型竞技场Code Arena上,智谱GLM模型在代码生成能力上与Anthropic、OpenAI等国际公司的模型并列全球第一。然而,算力瓶颈仍是现实挑战。阿里巴巴、腾讯等企业在业绩会上多次提及高端芯片获取受限的问题,而DeepSeek今年的迭代节奏也有所放缓,市场普遍认为其背后存在算力资源约束。
作为当前全球范围内仍主力使用的AI算力芯片,H200采用台积电4nm工艺,搭载141GB HBM3e显存,带宽达4.8TB/s,FP8算力接近4PFLOPS,这一性能水平使其能够更流畅地处理千亿级参数大模型的训练与推理任务。如果放开销售,短中期可缓解中国AI产业对于高端算力的需求,推动国内AI大模型开发进一步加速迭代以及AI应用落地。
此外,高阶算力的引入将直接刺激数据中心内及数据中心间超高速互联的需求。光模块作为数据中心内设备互连的关键组成部分,其需求与算力芯片的部署量直接相关。在典型部署中,单张H200 GPU常需2个800G光端口通过双链路聚合实现1.6Tbps带宽,以避免内存数据积压,对应比例约为1:2(基于800G模块);但在大规模集群中,为保障跨节点通信和带宽冗余,比例通常提升至1:3至1:4。这也意味着,一张H200GPU芯片可能需要3个及以上800G光模块与之配套。
国产AI芯片:
从产业角度看,目前H200的应用场景并不会和国产算力芯片直接竞争,H200主要应用场景集中在大模型训练环节,能充分发挥其算力、带宽、互联、集群稳定性等优势。而国产算力处在放量早期,还是以推理场景的适配为主。
更深层次看,“近渴”既要解,“远水”更要谋。
尽管H200有望回归,但美国政府明确排除了更先进的Blackwell和Rubin芯片,意在固化至少一代的技术代差。而许可所附带的苛刻条件,反而从侧面强化了我国攻坚国产算力体系的战略定力,依赖外部许可的算力模式在战略上不可持续,安全、合规性尚有缺陷,国产替代仍是大势所趋,国内政策加注自主创新的支持力度不会减弱。
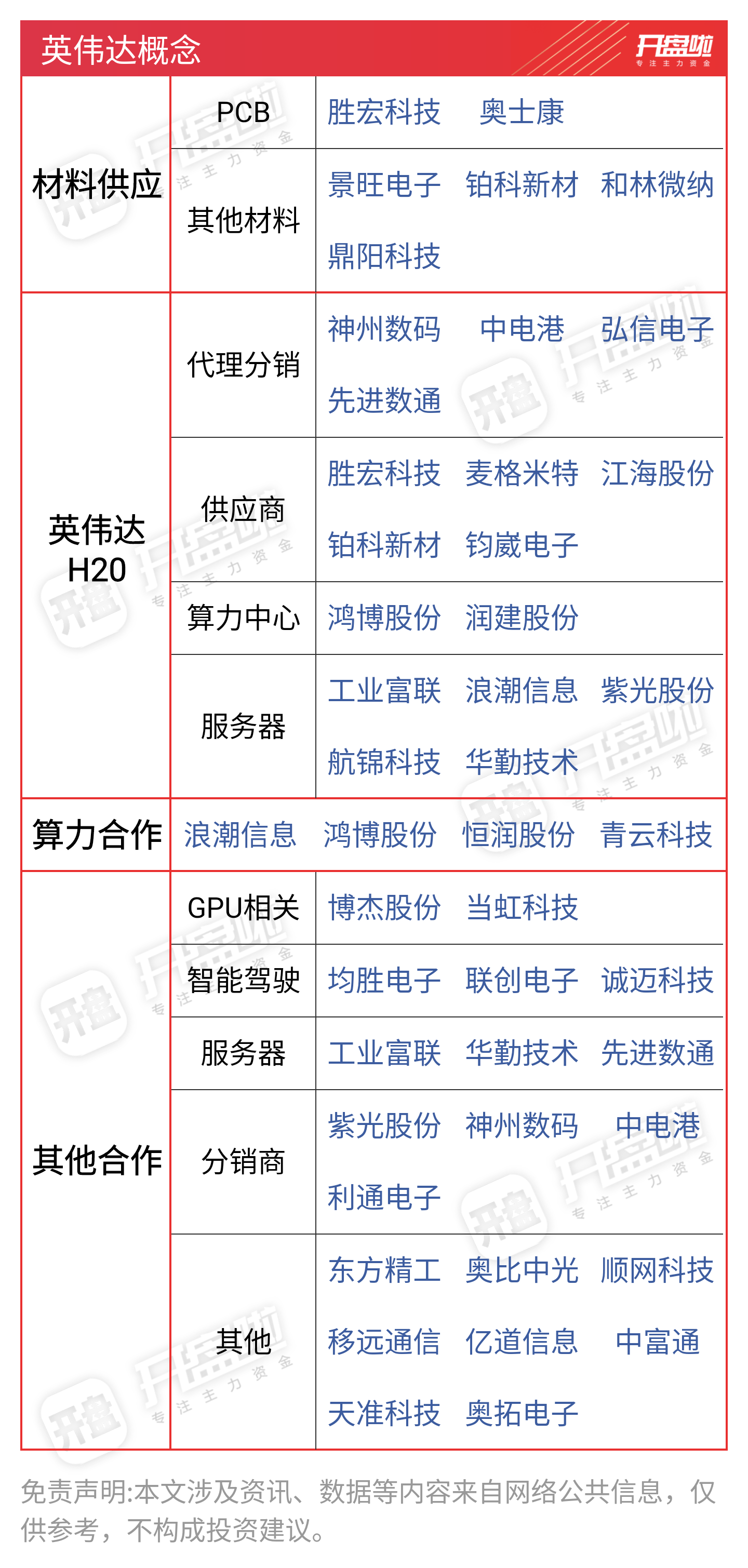
英伟达概念一览: