
FP8(8位浮点数)的主要缺点为精度仅为8位,相比FP16(16位)或者FP32(32位)能够提供成倍的算力和缩短计算时间,但其精度大幅降低,所以需要通过精度训练来更好的保持模型精度。对于各行各业的“大模型”FP8混合精度预训练技术等显得尤为重要,且具有“先发优势”。涉及FP8混合精度训练技术的上市公司如下:
1. 佳都科技,公司基于FP8混合精度预训练等技术,实现知行大模型训练效率较2024年初提升超150%,并在国产千卡GPU集群上完成了大模型优化训练方法的验证,知行交通大模型迭代到2.0版本(下图)

2. 开普云,在模型深度适配环节,基于硬件特性开展大模型优化,实施模型并行策略、混合精度训练和显存优化,提升模型推理效率与资源利用率。
3. 大华股份,支持FP32和FP8混合精度训练,以在保持模型精度的同时最大化显存利用率和计算效率。
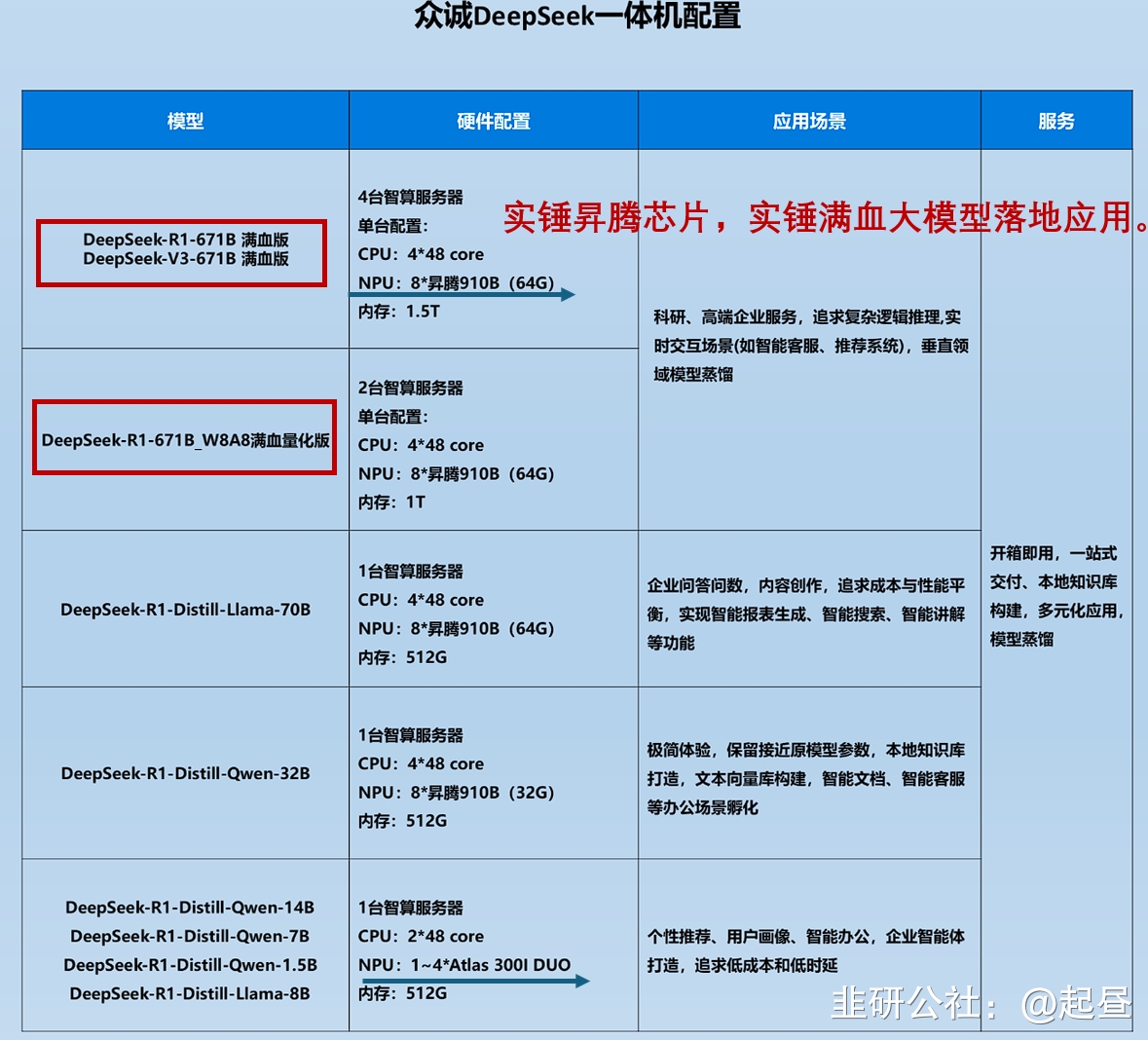
4. 众诚科技, 算法自演进优化:不断迭代提升算法精度,训练新算法。方案独有的多维度AI引擎可结合边缘测算力和AI算法,卸载前端数据滞留量,让AI稽核能够更好实现算法的优化和训练(下图),产品包含基于昇腾910系列芯片部分、deepseek一体机且为超聚变分销商和华为智能计算分销金牌商(附图)

5. 博实结,deepseek+精度无损模型研发 :深度学习网络的低比特在线量化训练,以更低的计算达到与同等参数量模型的浮点模型相当的性能。


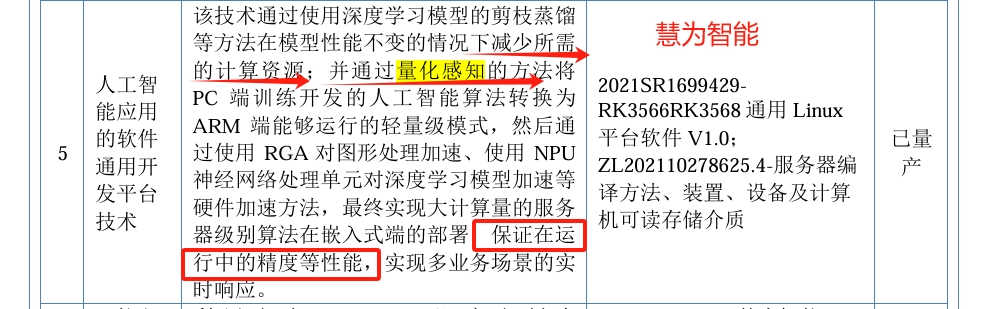
6. 慧为智能,人工智能应用的软件通用开发平台技术,深度学习模型的剪枝蒸馏等方法在模型性能不变的情况下减少所需的计算资源,通过量化感知等方法保证在运行中的精度等性能(下图)
附图:





$同惠电子(SZ833509)$ $海达尔(SZ836699)$
以上仅供FP8技术交流学习,不做投资建议,截图来自公告、公众号和网络,不做投资依据。
