
据媒体报道,2025中国算力大会将于8月22日至24日在大同举行,本届大会以“算网筑基 智引未来”为主题。相关数据显示,截至今年3月,在用算力标准机架达1043万架,智能算力规模达748 EFLOPS(每秒百亿亿次浮点运算)。
市场研究机构IDC预计,未来两年中国智能算力规模将保持高速增长。2025年中国人工智能算力市场规模将达到259亿美元,同比增长36.2%。中金公司指出,大模型行业领军者正通过技术迭代及客户黏性,使得追赶者不得不进行“算力抢筹”来避免被时代淘汰。北美模型更新迭代+推理应用落地已在当下模型代际上实现初步闭环,算力在后GPT-5时代依然为“硬通货”。
 该大会于2025年6月26日在北京举行,聚焦AI算力变局,邀请近30位重量级嘉宾探讨国产AI算力突围、智算中心技术创新等议题。大会明确以DeepSeek为代表的大模型技术为核心讨论对象,分析其推动的算力需求增长与国产化趋势。分会场的闭门研讨会(如超节点技术研讨)涉及DeepSeek相关技术应用,参会者需持有特定门票或邀请函。展区中,中昊芯英等企业展示了与DeepSeek适配的算力解决方案,间接体现其技术生态的参与。eepSeek还参与了同期或同主题的其他活动,例如深圳AI算力产业大会(展示大模型一体机)。YEF2025专题论坛(探讨国产算力替代英伟达)。
该大会于2025年6月26日在北京举行,聚焦AI算力变局,邀请近30位重量级嘉宾探讨国产AI算力突围、智算中心技术创新等议题。大会明确以DeepSeek为代表的大模型技术为核心讨论对象,分析其推动的算力需求增长与国产化趋势。分会场的闭门研讨会(如超节点技术研讨)涉及DeepSeek相关技术应用,参会者需持有特定门票或邀请函。展区中,中昊芯英等企业展示了与DeepSeek适配的算力解决方案,间接体现其技术生态的参与。eepSeek还参与了同期或同主题的其他活动,例如深圳AI算力产业大会(展示大模型一体机)。YEF2025专题论坛(探讨国产算力替代英伟达)。
而本周DeepSeek 新发布的V3.1 版本。这可以看作是其 V3 系列的一次重要升级,经业内人士体验后,完全属于全新的架构。为下一步推出R2版本做出了很好的铺垫。
核心升级亮点- 更长的上下文理解:V3.1 的上下文窗口(Context Window)从之前的 64K tokens 扩展到了 128K tokens。这意味着模型现在能处理更长的文档(约10万-13万汉字,相当于两本200页的小说或一篇超长的博士论文),在进行长文档分析、代码库理解或维持长时间对话时,上下文连贯性和准确性会更好。
- 参数与架构:模型的总参数量达到了 6850亿 (685B),采用了稀疏混合专家架构(MoE),每次推理时仅激活370亿参数,这有助于在保持强大性能的同时控制计算成本。同时,模型支持 BF16、FP8 (F8_E4M3) 和 F32 多种张量格式,为开发者在不同硬件上进行优化提供了灵活性。
- 编程能力显著提升:在 Aider 编程基准测试中,V31 取得了 71.6% 的得分,这个成绩超过了 Anthropic 的 Claude 4 Opus。同时,其推理和响应速度也非常快。
- 推理与搜索能力增强:模型内部集成了特殊的“搜索”和“思考”token(如 <search>、<think>),这表明 DeepSeek 可能在探索混合推理架构,使得模型能够进行更复杂的内部推理步骤甚至整合实时网络搜索功能,从而在动态场景中提供更准确和适应性的回答。
- 惊人的成本优势:完成一个完整的编程任务,V3.1 的估计成本仅为 1.01 美元左右。这与一些闭源竞争对手估计每个类似任务约70美元的成本相比,性价比非常突出。
- 开源与可及性:DeepSeek 继续秉承开源精神,将 V3.1 的模型权重在 Hugging Face 上发布,采用 MIT 许可证。这允许全球的开发者和研究人员自由下载、微调和部署,极大地降低了使用门槛并促进了创新。
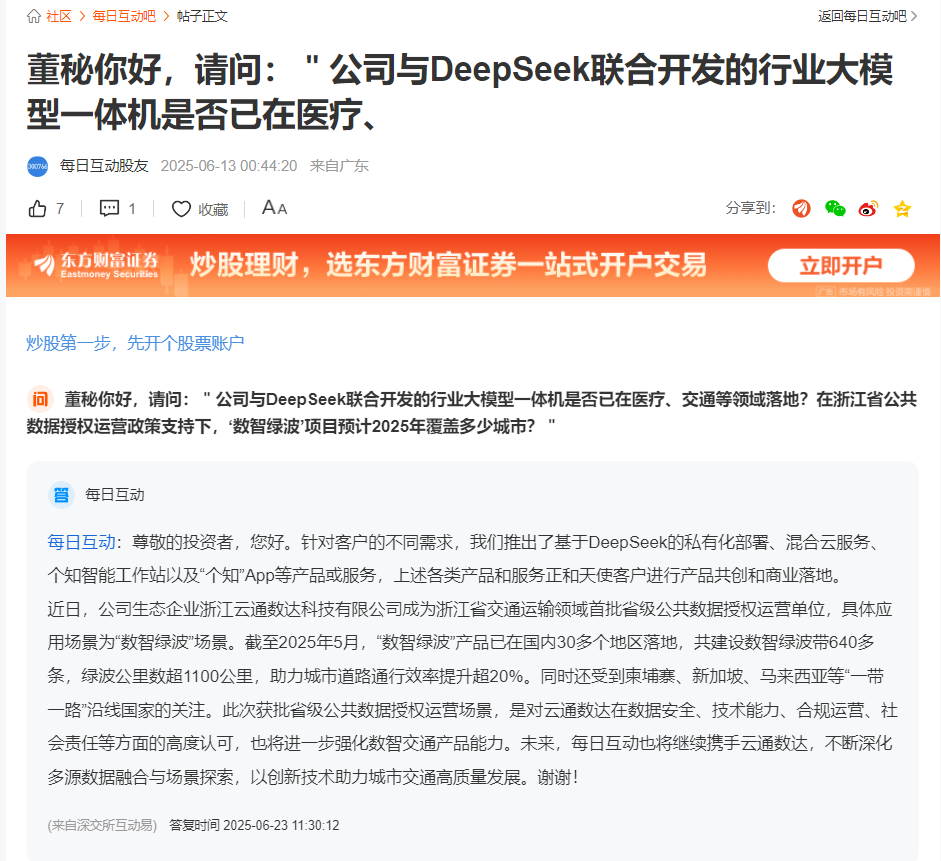
 每日互动(300766.sz)通过全资子公司应景科技持有幻方量化约14.5%的股权,而DeepSeek的母公司为幻方量化。每日互动的联合创始人徐进曾担任幻方量化技术负责人,而幻方量化创始人梁文锋同时是DeepSeek的创始人。每日互动与DeepSeek在技术层面合作紧密,例如接入DeepSeek大模型并完成私有化部署,同时否认了市场传言中“提供语料数据”的说法。双方在算力支持、数据优化及市场推广方面存在协同。例如,每日互动牵头的浙江大数据计算中心为DeepSeek提供算力支持,而DeepSeek的技术优势也助力每日互动提升数据处理能力。双方计划围绕垂直模型(如交通、医疗等领域)深化合作,探索“可信数据空间+可控大模型”的应用场景。
每日互动(300766.sz)通过全资子公司应景科技持有幻方量化约14.5%的股权,而DeepSeek的母公司为幻方量化。每日互动的联合创始人徐进曾担任幻方量化技术负责人,而幻方量化创始人梁文锋同时是DeepSeek的创始人。每日互动与DeepSeek在技术层面合作紧密,例如接入DeepSeek大模型并完成私有化部署,同时否认了市场传言中“提供语料数据”的说法。双方在算力支持、数据优化及市场推广方面存在协同。例如,每日互动牵头的浙江大数据计算中心为DeepSeek提供算力支持,而DeepSeek的技术优势也助力每日互动提升数据处理能力。双方计划围绕垂直模型(如交通、医疗等领域)深化合作,探索“可信数据空间+可控大模型”的应用场景。
 最后回到股市上,该股自上周大涨后已经回落缩量调整6日。最近两个交易日在10日均线附近得到支撑,有望在本次大会和新版本推出的双重利好消息刺激下再度挑战上周49.02元的月内新高!!!
最后回到股市上,该股自上周大涨后已经回落缩量调整6日。最近两个交易日在10日均线附近得到支撑,有望在本次大会和新版本推出的双重利好消息刺激下再度挑战上周49.02元的月内新高!!!
